Rétroingéniérie de Google Trends (1)
En janvier, j'avais proposé un utilitaire, le CaptuCourbe, pour extraire les valeurs d'une courbe, avec application possible à Google Trends. Depuis, l'outil s'est enrichi des couleurs par défaut des courbes Google, mais il manque toujours une donnée importante : quelle échelle verticale choisir ? Google prend en effet la précaution de cacher aux utilisateurs l'échelle utilisée. De plus comme les zooms ne sont pas permis, il n'est pas possible d'effectuer directement des comparaisons de courbes à différents ordres de grandeur. La hauteur maximum de courbe est en effet de 113 pixels, donc vous ne pouvez pas distinguer si un terme a été cherché 1000 fois, ou 10 000 fois moins qu'un autre.
Voici donc une hiérarchie de mots anglais, dans un ordre décroissant de recherches Google d'après Google Trends : of, free, sex, car, dog, gun, muscle, knife, torn, filming, separating, fooling.
On peut les utiliser pour créer une échelle pour Google Trends. Attention, elle ne sera pas précise (j'y reviendrai), mais permettra tout de même d'obtenir des valeurs quantitatives. Pour l'établir, j'ai procédé en recherchant conjointement dans Google Trends deux termes successifs dans la liste ci-dessus. Cela me permet d'évaluer le changement d'échelle pour chaque paire de successifs, en comptant la hauteur en pixel du maximum de chaque courbe. Une image est plus parlante que mes explications :
Comme je fais ça pour chaque paire de mots successifs, j'obtiens des valeurs de ce genre :
Comparaison cat ~ dog : 65 px ~ 113 px
Comparaison dog ~ phone : 69 px ~ 113 px
ce qui me permet de déduire en utilisant habilement des règles de trois que :
cat ~ dog ~ phone : 65 ~ 113 ~ 113*113/69=185,06
si l'on se base sur l'échelle de la première ligne ou bien :
cat ~ dog ~ phone : 69*65/113=39,69 ~ 69 ~ 113
si l'on se base sur l'échelle de la seconde.
Bref, j'ai reproduit ce raisonnement sur mes 11 mots pour obtenir les valeurs de maximum suivantes, en fixant la référence à fooling, et en appelant donc cette nouvelle unité le foo :
- fooling : 1 foo
- separating : 2,5 foo
- filming : 6,3 foo
- torn : 18 foo
- knife : 58 foo
- muscle : 120 foo
- gun : 240 foo
- dog : 640 foo
- car : 1500 foo
- sex : 3200 foo
- free : 6600 foo
- of : 16500 foo
 Par exemple ici environ 800 foo pour Manaudou en décembre 2007, à comparer avec les 240 foo du pic Bruni, ou les 470 foo atteints par Obama, les 1000 foo de Britney et les 3200 foo du tsunami de 2004 ou les 5700 foo de... Janet Jackson après le Superbowl 2004 !
Par exemple ici environ 800 foo pour Manaudou en décembre 2007, à comparer avec les 240 foo du pic Bruni, ou les 470 foo atteints par Obama, les 1000 foo de Britney et les 3200 foo du tsunami de 2004 ou les 5700 foo de... Janet Jackson après le Superbowl 2004 !Après l'annonce un peu commerciale de cette jolie petite échelle, l'honnêteté du scientifique m'oblige à quelques remarques :
- la marge d'erreur lors du calcul par enchaînement de règles de 3 successives : c'est le sujet de mon prochain billet et ce sera un peu technique (yaura même une jolie équation que ni Maple ni Mathematica n'arrivent à simplifier)... retenez que les nombres proposés ici doivent être valides à 10% près. Je me suis retenu de préciser plus de décimales, me souvenant de la sage annotation d'une prof de physique de lycée (au nom écorché par les sauvages utilisateurs de Note2Be) sur une de mes copies : "précision illusoire".
- non content de ne pas fournir l'échelle verticale de ses courbes, Google se permet aussi de les modifier fortement d'un jour à l'autre (c'est peut-être simplement un problème de discrétisation de la courbe réalisée "à la hache" sans se poser de question, mais dans ce cas étrange que les courbes de news en dessous soient identiques), comme le montre ce gif animé (créé avec le simplissime UnFreez) :
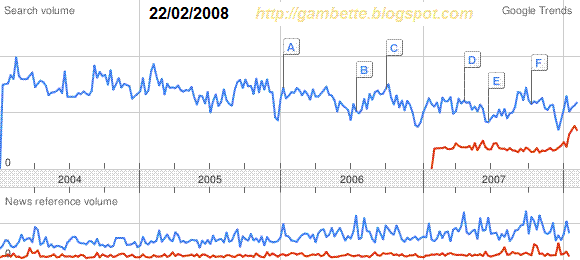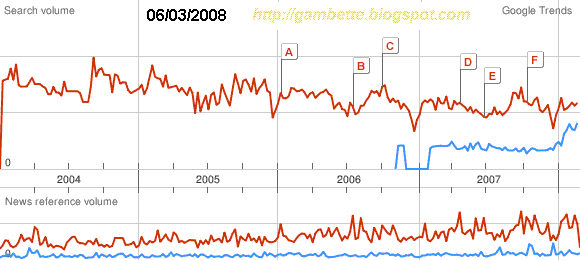 Attention donc si vous réutilisez un des mots ci-dessus comme référence, ne vous contentez pas de retenir la valeur du pic, ni même son positionnement, mais vérifiez en tentant de superposer la courbe de référence fournie sur ce billet, que la courbe de référence de l'image que vous voulez utiliser est bien à la même échelle, et tentez de corriger si ce n'est pas le cas.
Attention donc si vous réutilisez un des mots ci-dessus comme référence, ne vous contentez pas de retenir la valeur du pic, ni même son positionnement, mais vérifiez en tentant de superposer la courbe de référence fournie sur ce billet, que la courbe de référence de l'image que vous voulez utiliser est bien à la même échelle, et tentez de corriger si ce n'est pas le cas.- l'échelle reste relative, et pour en obtenir une absolue il faudrait savoir à combien de recherches Google exactement correspond 1 foo ? Toute idée de méthodologie pour connaître cette valeur est la bienvenue, pour l'instant la seule solution que j'aurais serait de créer un buzz artificiel de recherches Google, par un programme qui, un certain jour, à une certaine heure, irait rechercher un terme sur Google, et visiter une "page compteur" qui recenserait ainsi le nombre total de recherches Google sur ce terme. Encore faudrait-il avoir assez de volontaires qui accepteraient d'installer le programme, et je ne suis pas Vijay Pande... En attendant je peux remarquer que la courbe pour M6 direct a atteint 0,5 foo en février, alors que mon blog recevait environ 500 visites hebdomadaires pour ces mots-clé (pour lesquels je suis bien positionné). Bref, pour qu'un pic soit mentionné par Google Trends il faudrait cibler sur plus d'un millier de participants...
Ajout du 10/03 : je me rends compte que j'aurais peut-être dû mentionner, à propos de cette unité "foo", que le nombre de recherches auquel elle correspond est variable avec le temps. En effet les courbes Google Trends représentent une proportion des recherches sur certains termes par rapport à toutes les recherches Google. Ceci explique d'ailleurs la valeur impressionnante en foo de "Jackson". Par rapport au nombre total d'utilisateurs de Google en 2004 effectivement le buzz a été énorme, mais difficile de comparer de façon absolue en nombre de recherches 5700 foo de 2004 avec 800 foo de 2008... à moins que là aussi on puisse bricoler quelque chose ? Récupérer l'évolution du nombre de visiteurs ou de recherches Google depuis 2004, utiliser les courbes Alexa... à voir.
This post is translated to English: Reverse engineering Google Trends (1).
Fichiers source : les courbes Google Trends de chaque mot sont liées ci-dessus, voilà le fichier tableur qui a servi au calcul des valeurs en foo (attention c'est un fouillis monstre, plus de détails dans le prochain billet).
 Voter pour ce billet sur Wikio
Voter pour ce billet sur Wikio








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
11 commentaires:
Votre travail est tres interessant.
Une remarque votre post serait plus lisible si vous laissiez les legendes des courbes.
Quelles légendes ?
Si vous parlez de celles des images liées depuis les mots fooling, separating, filming... c'est vrai qu'il y a une ambiguité : la courbe du dessous est celle correspondant au premier mot du nom de fichier (la courbe bleue de http://philippe.gambette.free.fr/Blog/GoogleTrendsScale/BetterScale/05KnifeMuscle.png est celle de "knife"). Ceci dit je n'ai rien effacé moi-même, c'est juste Google qui n'inclut pas la légende des couleurs dans ses images mais la met au-dessus de l'image, en HTML. Je vais les ajouter pour plus de clarté.
Bonjour,
Intéressant comme démonstration.
Ce que je vous propose c'est de discuter en privé - jeanmichel @ gmail.com - afin de trouver la valeur du "foo" nous devrions pouvoir nous baser sur les impressions de publicités "adwords" sur un terme précis.
Bonjour,
Tout d'abord, oui, les résultats ne sont pas fiables, car très variables. J'en ai fait la malheureuse expérience en suivant jour après jour certains buzz via cet outil.
Ensuite, l'analyse se base sur deux choses dont je ne suis absolument pas certain qu'elles soient exactes :
- l'axe des ordonnées commencerait à 0 'foo'. => non, la preuve, certaines requêtes très recherchées connaissent un jour un pic incroyable (exemple : "air", avec mac air). Résultat, sur la période précédent la sortie du joujou d'Apple, le mot "air" est proche de zéro. Alors que c'est faux (on le voit quand on choisit une année en particulier).
- l'échelle est toujours la même. ==> Je pense, à mon humble avis, que l'échelle varie en fonction de la requête : très petite pour le gros buzz, très grande pour les mots qui varient à peine. C'est pour mieux voir les variations de fréquences de recherches.
L'analyse faite ici est sans doute l'une des meilleures qu'il m'ait été donné de lire, mais pas fiable. Non pas dû au travail d'analyse, mais à l'outil utilisé ;)
@tomhtml : je ne suis pas d'accord avec le premier argument. Voilà mon avis : sur la courbe, 0 pixel en ordonnée correspond effectivement à 0 recherche. En revanche une hauteur de 113 pixels correspond toujours au maximum du nombre de recherches sur la période ciblée (donc effectivement il y a un changement d'échelle selon la hauteur du buzz). Je m'explique avec l'excellent exemple du Mac Air ;) :
- courbe de 2004 à 2008 : effectivement la courbe est très basse avant 2008 (2 pixels de haut), en comparant avec knife je trouve un pic à 70 pixels soit environ 35 foo pour 2008, en revanche avant 2008, les 2 pixels correspondent à environ 1 foo (ce qui est confirmé par la comparaison foolin/mac air qui ont des niveaux semblables avant 2008).
- courbe en 2008 : Mac Air atteint presque le niveau de knife (100 pixels au lieu de 113, c'est à dire 88%), mais attention, le max de knife en 2008, atteint le 1° janvier, est inférieur au max de knife de 2004 à 2008 ! Si on mesure sur la courbe de 2004 à 2008 la valeur de knife au premier janvier, on trouve 73 pixels soit 40 foo. Maintenant, sur la courbe de 2008, 88% fois 40 foo = 35 foo... ce qui correspond à la valeur trouvée sur la courbe de 2004 à 2008 !!!
- courbe en 2007 : on utilise la courbe de fooling en 2008 pour calculer qu'au 1° janvier 2008, fooling est à 0,5 foo environ. Or on voit sur la courbe de comparaison en 2007 que Mac air est en moyenne deux fois plus grand que fooling, soit 2*0,5 foo = 1 foo, à nouveau on retombe sur la valeur estimée avec la courbe de 2004 à 2008 !
Alors, convaincu ;) ?
Un peu plus, mais pas encore à 100%
Il faudrait que Google nous sorte une API pour son google trends, qu'on puisse faire ce genre de calculs de manière plus automatisée ;)
Je reste aussi convaincu que l'axe des abscisses ne correspond pas à 0 recherches, mais plutôt à un nombre relativement petit (genre 10000).
PS : je vois que le pic de Carla Bruni (décembre 2007) correspond au pic du Kosovo (février 2008) pour ces 12 derniers mois. Est-ce qu'en reprenant tes calculs juste pour ces deux mois là, en comparant avec knife ou autre, ça corrobore tes dires ?
Ohoh, joli PS, tu me pousses dans mes derniers retranchements ! C'est une remarque très intéressante, parce qu'effectivement si on regarde simplement les max ça ne semble pas marcher : sur la courbe par mois en comparant avec "gun", le pic de Kosovo semble beaucoup plus bas que Bruni.
Mais ceci a une autre explication (et c'est super que tu m'aies fait réfléchir à ça), c'est la discrétisation de la courbe. Si on la considère sur une année, j'ai l'impression qu'il y a 51 segments dans la courbe, c'est à dire que chaque point correspond à une semaine. Si tu compares les courbes Bruni/Gun en 2007, et Kosovo/Gun en 2008, tout va bien, elles ont encore la même hauteur.
Mais dès lors qu'on passe au zoom sur un mois, chaque point correspond à une journée. Là tu te rends compte que certes le pic de Kosovo semble plus bas, mais il est plus large que celui de Bruni. Ainsi ça explique qu'en sommant sur 7 jours pour obtenir une semaine, on tombe sur la même valeur pour les courbes annuelles, et les courbes 2004-2008.
En résumé : attention au passage année -> mois. Pour être tout à fait rigoureux j'aurais dû définir le foo en précisant que c'était une valeur de proportion par rapport au nombre de recherches Google pendant une semaine.
Je suis même un peu approximatif en parlant de somme (2 paragraphes au-dessus en gras). En effet, la valeur de la courbe sur une semaine ne correspond pas exactement à la somme des valeurs sur les 7 jours à cause de cette histoire de proportion. Si un mot est cherché n1 fois lundi, n2 fois mardi... n7 fois dimanche, et que le nombre total de recherches sur chaque jour est t1 pour lundi, t2 pour mardi... t7 pour dimanche, faire la somme reviendrait à calculer n1/t1 + n2/t2 + ... + n7/t7.
Or il est naturel que Google propose les vraies proportions par semaine, c'est à dire : (n1+n2+...+n7)/(t1+t2+...+t7), qui certes doit s'approcher de l'expression précédente, en admettant que t1, t2, ... t7 sont très semblables (il y a à peu près autant de recherches Google chaque jour de la semaine).
Tout s'explique alors ;-)
Bon maintenant reste à savoir l'échelle.
Pour cela c'est faisable : il suffit de trouver qqun qui est premier sur un mot clé (dans toutes les langues si possible) et lui demander ses stats de visiteurs en provenance de Google. Après, on connait le pourcentage d'internautes qui ne cliquent que sur le premier résultat. Et on devine le nombre de recherches totales, et donc l'échelle en "foo" :)
Tiens tiens, des estimations de nombres de recherches sur certains mots-clés sont disponibles sur http://freekeywords.wordtracker.com/
Je regarde dès que possible si elles sont cohérentes avec mes chiffres et me permettent de préciser la valeur du foo...
Wordtracker est un outil principalement anglophone, les estimations sur les mot clés fr seront erronées et non significatives.
sid, un petit lien pour justifier cette remarque (d'autant que justement c'est sur des mots-clés de référence anglais que je travaille) ? En regardant très rapidement, leurs données me permettent d'estimer qu'un foo correspond environ à 2000 recherches par semaine, ce qui semble effectivement un peu sous-évalué.
Je suis aussi tombé sur GTrends made easy qui prétend fournir une approximation du nombre de recherches sur des mots-clés, on va voir ce que je peux tirer de leurs données.
Enregistrer un commentaire