De retour après avoir passé du temps à l'Inathèque, déménagé, commencé ma thèse, et préparé mes premiers enseignements, me voilà prêt à décortiquer un nouveau phénomène viral, après la F-list, la pétition "Touche pas à mon ADN".
Là malheureusement, on n'a pas autant d'informations sur la transmission du phénomène que pour les F-lists, mais on va essayer de tirer quelques conclusions à partir de la jolie base de plus de 200 000 signataires disponibles sur le site TouchePasAMonAdn.com. Première difficulté, récupérer la base de données, qui est répartie en plusieurs feuilles de 400 noms. Pour ça j'ai mon "aspirateur" personnel, qui visite les pages voulues en extrayant les informations utiles du code HTML des pages. Une petite difficulté supplémentaire : la liste se met à jour pendant l'aspiration, il a donc fallu mettre en place a posteriori une détection automatique des signataires qui avaient été enregistrés deux fois : en fin de page et en début de page suivante. Ca paraît relativement simple, hein ? Sauf que la tâche se complique quand les organisateurs décident de nettoyer leur base de signataires d'avant le 11 octobre, en réorganisant au passage de façon apparemment aléatoire (rangée ni dans l'ordre alphabétique, ni chronologique) la liste des signatures avant cette date.
Alors pourquoi une telle réorganisation ? Tout d'abord, à cause des signataires qui cliquent mal : beaucoup de doublons apparaissent dans la liste brute. Ensuite, à cause des petits rigolos qui font des blagues. En voilà un petit florilège (vous vous rappelez des Zidane et Chirac d'Unitaid ?), attention la finesse n'est pas toujours au rendez-vous...
04 octobre 2007, 02:15;nicolas sarkozy;nabot présidentiel (république bananière);
04 octobre 2007, 12:29;Nicolas Sarkozy;;
04 octobre 2007, 13:01;Nicolas Sarkozy;Président de rien du tout;
04 octobre 2007, 14:54;NICOLAS SARKOZY;président (france);
04 octobre 2007, 17:43;Nicolas Sarkozy;Président (aucune);
04 octobre 2007, 18:38;nicolas sarkozy;président;
04 octobre 2007, 20:52;Nicolas Sarkozy de Nagy Bocsa;Président, enfin... je crois;
16 octobre 2007, 08:36;nicolas sarkozy;président des francais;
03 octobre 2007, 11:00;brice hortefeux;schizophrène (Dictature Sarkozyenne);
03 octobre 2007, 11:52;BRICE Hortefeux;Fuhrer (République Francaise);
03 octobre 2007, 13:41;hortefeux brice;raciste 2nd;
03 octobre 2007, 17:12;Brice HORTEFEUX;;
03 octobre 2007, 17:28;Brice Hortefeux;Face de pet;
03 octobre 2007, 21:47;BRICE HORTEFEUX;ministre de la betise;
03 octobre 2007, 22:50;Brice Hortefeux;futur ex-Ministre;
03 octobre 2007, 23:13;Brice Hortefeux;;
04 octobre 2007, 16:12;brice hortefeux;;
04 octobre 2007, 16:13;Brice HORTEFEUX;Ministre (SARKOLAND);
16 octobre 2007, 12:16;brice hortefeux;;
03 octobre 2007, 21:59;Thierry Mariani;Député cocu;
03 octobre 2007, 18:48;thierry mariani;député (bientôt chômeur);
12 octobre 2007, 15:04;Thierry Mariani;député;
13 octobre 2007, 21:04;THIERRY MARIANI;MINISTRE : vous êtes tous des rigolos !;
03 octobre 2007, 10:53;GEORGES BUSH;u want2fukme;
03 octobre 2007, 22:22;jorge bush;rongeur (otan);
04 octobre 2007, 15:37;georges bush;;
04 octobre 2007, 23:30;GEORGES BUSH;USA;
13 octobre 2007, 22:54;Debeuliou Bush;President of the United-States of America;
16 octobre 2007, 06:33;georges bush;;
12 octobre 2007, 18:49;François Mitterrand;Illusionniste;
13 octobre 2007, 17:41;Chirac Bernadette;Pute des routes;
16 octobre 2007, 10:57;Jacques Chirac;ancien Président de la République;
03 octobre 2007, 11:35;zidane zinedine;retraité;
03 octobre 2007, 18:05;Zinedine Zidane;ancien footballeur;
03 octobre 2007, 22:50;zidane zinedine;footballeur;
03 octobre 2007, 23:23;zinedine zidane;footballer (OM);
04 octobre 2007, 23:27;Zinédine Zidane;Footballeur retraité;
15 octobre 2007, 18:38;Zinedine Zidane;retraitée du sport (les pervers);
15 octobre 2007, 19:06;Bernard Kouchner;National Socio-traitre (Nazie) (Heil Hitler !);
04 octobre 2007, 23:32;KOUCHNER Bernard;Extérieur du Ministère;
16 octobre 2007, 09:26;Francois Bayrou;Clown;
04 octobre 2007, 10:35;fadela amara;traitre (ump);
17 octobre 2007, 07:20;test test;test (test);
17 octobre 2007, 07:17;Kipeutebattre croustibat;poisson pané (findus);
16 octobre 2007, 02:02;Kylie Minogue;Chanteuse;
Depuis, certains de ces noms ont disparu : les Sarkozy et Hortefeux d'avant le 11 octobre. Il reste les Zidane. J'imagine donc qu'une certaine partie du tri a été faite manuellement
(pour automatiser un peu tout ça je suggérerais de classer les signataires par ordre alphabétique et vérifier les groupes de personnes qui ont le même nom et prénom, ou encore d'utiliser FuryPopularity sur les noms de tous les signataires pour identifier les noms connus... et donc suspects). La partie automatique de suppression des répétitions a visiblement été efficace, puisqu'elle a fait passer le nombre de signataires du 4 octobre de 41000 à 33000 environ, pour le 3 octobre de 30000 à 28000. L'ordre de grandeur est toutefois respecté, ce qui peut rassurer les quelques visiteurs étonnés par ces doublons.
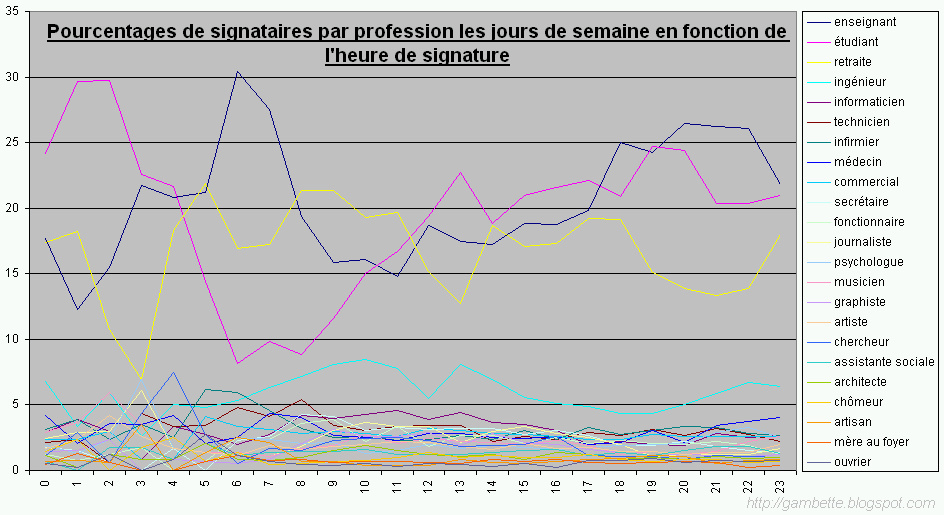
Bref, même si la récupération de la base n'est pas immédiate, elle est possible, et je l'ai bien vite enregistrée en supprimant les données nominatives, gardant seulement l'heure et la profession pour chaque signataire. La profession, je la garde en réserve pour la
deuxième et la
troisième partie de ce billet, regardons seulement l'évolution des signatures pendant la première quinzaine de la pétition :
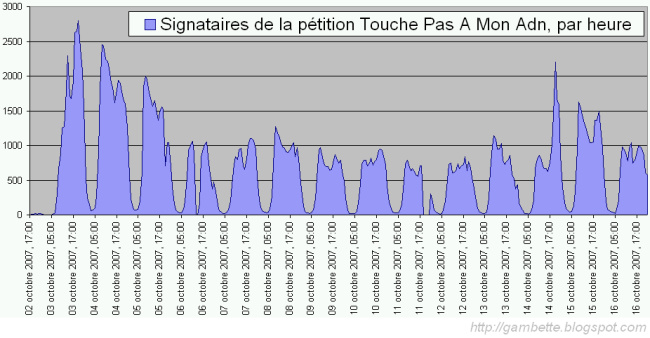
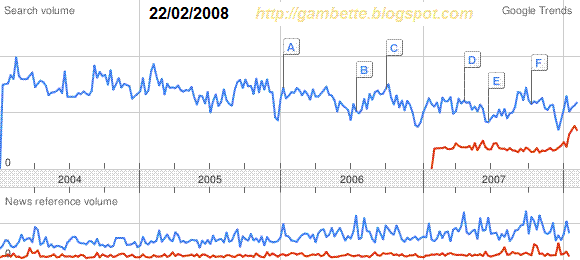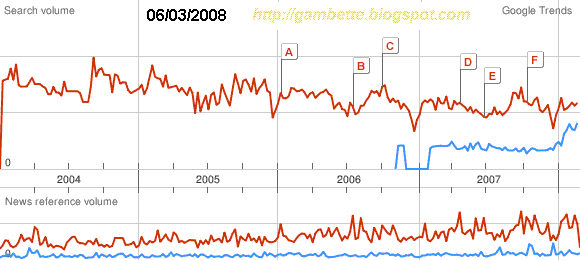
Remarquons d'abord le joli démarrage, qui doit laisser rêveur tout adepte de marketing sur internet... Est-ce que la "qualité du produit" a suffi à attirer une telle foule ? Quels ont été les relais publicitaires pour faire connaître le site aussi vite ? Médias traditionnels, bouche à oreille, blogs, mails ? S'il n'est pas évident de le déterminer (le décollage commence à 8h du matin !), on peut en revanche remarquer une forte corrélation entre le nombre de billets de blogs citant la pétition, ou son adresse, et le nombre de signataires :

Notre tableur préféré nous donne un coefficient de corrélation de 0.80 entre le nombre de signataires et le nombre de billets quotidiens contenant "Touche pas à mon ADN" d'après Blogsearch, 0.76 avec le nombre de ceux qui contiennent le lien vers touchepasamonadn.com. Remarquons aussi que les deux courbes Blogsearch très proches avant le 13 octobre divergent ensuite. Pourquoi ?
La clé de l'énigme, c'est le meeting concert
Touche pas à mon ADN, dont les gens ont visiblement parlé sur leur blog sans donner l'adresse de la pétition. Toutefois l'événement a eu un retentissement médiatique qui se visualise très bien le 14 octobre au soir avec deux pics de signatures vers 19h50 et 20h20, et qui redonne de l'énergie au nombre de signatures par heure.
Enfin vous aurez noté sur le graphique de l'évolution des signatures deux interruptions du site, le 11 octobre au soir, et le 6 octobre avant 17h. Il semble tout de même avoir tenu le coup aux moments les plus critiques.
Pas encore efficace, cette pétition montre toutefois quelques conditions nécessaires pour un succès. Un relai médiatique, une solide structure technique pour accueillir les signatures voire vérifier leur authenticité. Où s'arrête l'initiative populaire et où commence le lobbying super organisé et forcément bien financé ? En attendant de telles initiatives permettent au moins de maintenir une certaine vigilance... et nous donner des indications sur les horaires de surf des étudiants, des enseignants, des retraités, des chercheurs, des ingénieurs. A suivre très bientôt,
dans le prochain billet !



 Voter pour ce billet sur Wikio
Voter pour ce billet sur Wikio























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}