Eurovision, géopolitique et phylogénie, partie 1/2 : des pourcentages d'amitié aux distances d'amitié
Un peu plus d'un an que ce blog existe, je me permets donc de faire un petit bilan, avant de passer au sujet principal de ce billet, qui répond justement au premier posté ici l'an dernier, à propos de l'Eurovision.
Un rythme pas trop inégal d'un peu moins d'un billet par semaine, une collection de petits outils informatiques qui s'agrandit régulièrement (celui pour créer des nuages de mots, lancer de multiples requêtes Google, analyser les logs MSN), quelques idées de futurs billets en tête, tout cela m'incite à continuer dans la même veine. Surtout que ce blog m'est finalement très utile. Pour mettre à l'épreuve quelques idées reçues (sur la collusion des votes à l'Eurovision, la qualité des sondages...), ou quelques idées tout court (l'utilisation des moteurs de recherche pour l'orthographe et ses limites, le déclin de la qualité de traduction des titres de films...). Mais il m'a aussi permis quelques découvertes inattendues, sur la datation du big bang du web, la spécificité francophone de l'abréviation "MacDo" ou le syndrôme des moutons de Panurge chez les députés. Et je profite souvent d'avoir posté un billet pour approfondir un peu sur le sujet (certes, il serait préférable de le faire avant, mais je ne tiens pas vraiment à me lancer dans une étude biblio systématiquement...).
Je ne suis pas le premier à me féliciter des avantages du blog en tant qu'outil comunautaire, mais les discussions faisant suite à certains posts, qu'elles aient lieu sur le blog ou non, ont toujours été très enrichissantes. Et elles ont parfois rejoint directement un sujet de recherche scientifique "sérieux", que ce soit pour l'illustrer (le Voronoï des McDos parisiens par exemple, pour illustrer le jeu de Voronoï, ou la visualisation en plan de métro pour l'isomorphisme de graphes), le motiver (de nombreuses problématiques sur les distances en phylogénie), ou rester à sa frontière en attendant des liens éventuels (le corpus de la F-list et les modèles de diffusion ou les communautés dans les blogs). Bref, le blog qui s'introduit comme une des composantes de la méthode scientifique, ça me plaît bien, et je vais continuer à véroniser encore un peu...
Et pour aujourd'hui, ce sera un problème qui me trotte dans la tête depuis quelque temps déjà. Cela fait belle lurette que l'arbre phylogénétique a été utilisé pour représenter autre chose que des relations de parenté entre espèces ou gènes... C'est simplement un excellent outil de visualisation, qui est très expressif pour représenter des données séparées par des distances connues, plus en tout cas qu'un plongement dans le plan (en deux dimensions, parfois même plus expressif qu'un plongement en 3D...), bien qu'il soit planaire.
Le problème est que pour des applications non bioinformatiques, les distances utilisées doivent ressembler à des distances le long de branches d'un arbre pour que celui-ci soit vraiment expressif. On peut se rappeler de l'arbre des thèmes de la présidentielle de Jean Véronis construit à partir des "distances Google normalisées", qui était beaucoup plus expressif quand on fixait une longueur unitaire à toutes les arêtes de l'arbre. Si on ne le faisait pas, on obtenait une sorte d'étoile, avec des branches menant aux feuilles toujours très longues.
J'avais obtenu pour l'Eurovision l'an dernier un arbre assez satisfaisant, mais celui-ci représentait seulement les proximités de votes entre les pays : deux pays étaient rapprochés s'ils votaient de la même façon, et pas s'ils votaient l'un pour l'autre. Or ce second problème semble plus intéressant quand on désire quantifier les effets du vote d'amitié entre pays voisins. Reste à trouver une distance d(i,j) qui reflète que le pays i avantage le pays j dans ses votes, et inversement. Si vous voulez éviter ces détails techniques croustillants et passer directement aux résultats... vous n'avez plus qu'à attendre la seconde partie du billet
Un des défis est que la distance soit normalisée, c'est à dire qu'un pays n'ayant pas souvent participé, ou ayant reçu peu de points, ait des distances avec les autres comparables à celles d'un pays souvent présent au palmarès. Pour cela je propose donc l'approche suivante, qui m'a surpris par ses résultats qui semblent robustes (j'obtiens pour cette distance des arbres très similaires avec diverses méthodes de reconstruction, je reviendrai là-dessus...).
J'appelle P(i->j) le pourcentage des points donnés par le pays i au pays j, parmi tous les points reçus par le pays j. Un des avantages de cette approche est que le nombre de compétitions auxquelles ont participé i et j importe peu (ce qui est intéressant parce que par exemple l'Albanie n'a participé qu'une fois de 1975 à 2004, alors que la Grande-Bretagne était présente tous les ans). On dispose donc d'un ensemble de données normalisées P(i->j) pour chaque couple de pays, et on voudrait les transformer en données de distances qu'on note d(i->j). En particulier on veut qu'elles soient symétriques, c'est à dire que d(i->j) = d(j->i), et on veut que d(i->j) soit petit quand P(i->j) et P(j->i) sont grands, c'est à dire que d soit une fonction décroissante par rapport à P. Mais quelle fonction décroissante choisir ?
Pour trouver cette fonction convenable pour d, commençons par raisonner sur de petits exemples, c'est à dire de petits arbres binaires non enracinés où d est donc connue, et où on cherche à déterminer pour chaque noeud i des pourcentages P(j->i) raisonnables. On commence par l'arbre le plus simple possible, à 3 feuilles, en figure (a) ci-dessous. Chaque feuille étant placée à distance égale de ses deux voisins, les pourcentages des deux voisins doivent être égaux, c'est à dire par exemple pour la feuille 2 que : P(1->2) = P(3->2) = 1/2. Supposons maintenant qu'on insère une feuille 4 dans l'arête qui aboutit à 3, comme illustré dans la figure (b). Le sous-arbre contenant 1 et 2 n'étant pas changé, on garde P(1->2) = P(2->1) = 1/2. Il reste donc 50% des points reçus par 1 à attribuer à 3 et 4, qui sont tous deux à la même distance de 1, donc : P(3->1) = P(4->1) = 1/4. En procédant de même pour chacune des autres feuilles, on obtient les pourcentages indiqués dans la figure (b).
Supposons maintenant qu'on insère une feuille 4 dans l'arête qui aboutit à 3, comme illustré dans la figure (b). Le sous-arbre contenant 1 et 2 n'étant pas changé, on garde P(1->2) = P(2->1) = 1/2. Il reste donc 50% des points reçus par 1 à attribuer à 3 et 4, qui sont tous deux à la même distance de 1, donc : P(3->1) = P(4->1) = 1/4. En procédant de même pour chacune des autres feuilles, on obtient les pourcentages indiqués dans la figure (b).
De même, si on ajoute une nouvelle feuille, 5, on peut attribuer les points pour obtenir les pourcentages indiqués en figure (c). En fait la procédure pour attribuer les pourcentages de points de la feuille i peut se voir ainsi : on part de la feuille i et on parcourt l'arbre : à chaque embranchement rencontré, on divise par deux le nombre de points attribué par chacun des sous-arbres délimités par l'embranchement. Cette technique permet bien d'arriver à un total de 100% des points attribués, pour chaque feuille.
La formule est donc la suivante pour P en fonction de d :
Au lieu d'utiliser les données brutes, on va effectuer une sorte de lissage en ajoutant le fait que tout pays donne de toute façon un point à tout autre pays. Ainsi, en notant p(i->j) le nombre de points réellement donnés à j par i, au lieu de définir :
Je suis allé faire un petit tour dans la littérature concernant le concours de l'Eurovision, et les moyens utilisés pour estimer une "distance Eurovision" entre les pays sont assez variés.
Il y a une sorte de référence en la matière, l'article de Fenn, Suleman, Efstathiou et Johnson de 2005 (paru cette année dans Physica A) qui propose plusieurs critères quantitatifs :
- ils considèrent pour chaque année le graphe formé simplement en mettant les pays comme noeuds et une arête entre deux noeuds si un pays a donné un ou des points à l'autre. Ils comparent les coefficients de clustering, et la distribution des degrés (des paramètres classiques en étude de réseaux sociaux), de ce réseau par rapport à un réseau correspondant à un concours attribuant les points aléatoirement.
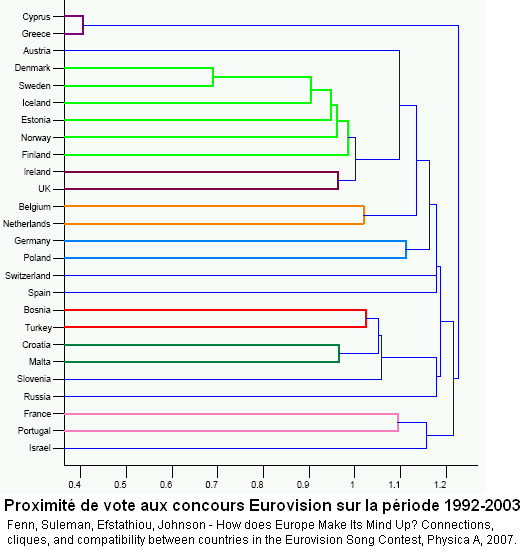
- pour dessiner un dendrogramme (une sorte d'arbre phylogénétique), ils ne se basent pas sur une distance indiquant l'affinité entre pays (qui était pourtant exprimée par le coefficient de clustering, et la distribution des degrés), mais reviennent à une approche plus classique de comparaison des votes, en utilisant le coefficient de Pearson (donc un peu plus sophistiqué que la simple somme des valeurs absolues des différences que j'avais utilisée l'an dernier), et en utilisant la méthode UPGMA pour la construction de l'arbre. En tout cas l'arbre obtenu fait bien ressortir quelques signaux forts d'affinité de goûts entre pays.
L'analyse de Gatherer de 2006 cherche à identifier localement les collusions entre pays et leur évolution, mais ne fournit pas de panorama global.
L'article de Dekker, The Eurovision Song Contest as a 'Friendship' Network, propose un "score d'amitié" intéressant : il estime un score attendu en fonction des résultats globaux, et le score d'amitié reflète la différence entre le nombre de points attendu et le nombre de points réellement obtenus. Toutefois, l'auteur indique que la construction d'un arbre phylogénétique n'est pas appropriée en utilisant ces scores : ajouter un bruit aléatoire de 0 à 0,1% pour altérer les données fournit des arbres assez différents. C'est justement sur ce point que j'espère que la formule de distance présentée dans ce billet sera plus robuste.
 A noter aussi dans cet article le joli graphique en 3D représentant les points attribués entre pays en fonction de la proximité entre eux (calculée en terme de nombre minimal de frontières à traverser pour passer de l'un à l'autre).
A noter aussi dans cet article le joli graphique en 3D représentant les points attribués entre pays en fonction de la proximité entre eux (calculée en terme de nombre minimal de frontières à traverser pour passer de l'un à l'autre).Bref, tests et figures à venir, en attendant vous pourrez toujours aller voir la carte de l'Europe colorée en fonction des points attribués au concours 2007 sur Agoravox...
 Voter pour ce billet sur Wikio
Voter pour ce billet sur Wikio








{kind=link}
Aucun commentaire:
Enregistrer un commentaire