
Nouvelle chaîne dans ma boîte mail, nouvelle analyse de
mème sur ce blog (après la
F-list, et
fait-ou-pas) : le "
Scrabble International".
Il s'agit d'une liste de mots de 6 lettres, à laquelle on doit ajouter un mot français :
- de 6 lettres pas encore présent dans la liste
- ayant exactement une lettre de différence avec le mot précédent (dont les lettres sont éventuellement réordonnées).
Sont ajoutés le prénom et la ville du participant, ainsi que sa date de participation. Voilà l'exemple de la
liste que j'ai reçue (209 mots). J'en ai trouvé quatre autres sur le net, de
124,
85,
216 et
89 mots, qui montre que la liste a voyagé (par mail, pas sur la blogosphère apparemment) en Belgique d'où elle est partie, en France, en Algérie, en Suisse, au Canada, au Maroc... L'arbre de diffusion à gauche résume l'historique de ces listes.
Je me suis demandé quelle taille pourrait atteindre cette liste, en théorie. Eh oui, car en pratique, comme pour tous les mèmes, les participants ne suivent pas toujours les règles, éviter et tourbe sont deux fois dans la première liste, piéger et pingre dans la cinquième, et je ne parle pas de ceux qui oublient d'inscrire la date, ou prennent un malin plaisir à changer le format pour que je ne puisse pas récupérer toutes les infos facilement avec un script.
Bref, supposons que tout le monde suive les règles, le jeu correspond à construire un chemin qui ne repasse jamais pas le même sommet (en bleu dans l'illustration ci-dessous) dans un graphe :
- dont les sommets sont les mots français de 6 lettres
- dont les arêtes rejoignent deux mots qui ont une lettre de différence.
Quelles sont les propriétés de ce graphe ? Quelle est la taille du plus long chemin qu'il contient ? Est-ce que 6 lettres est la taille de mots la plus adaptée pour assurer le succès de ce mème ? Voici les quelques questions auxquelles je vais tenter de répondre dans ce billet, avant une suite éventuelle qui sera dédiée à une analyse des données des les 5 listes récoltées.
Première chose à faire, construire ce graphe à partir d'une liste de tous les mots français. Je récupère ça
chez un collègue marseillais, regroupe les mots par taille en passant tout en minuscules et en enlevant les lettres accentuées : 2 mots de taille 1, 81 de taille 2, 427 de taille 3, 1799 de taille 4, 5897 de taille 5, 13931 de taille 6... Tiens tiens, ça augmente comme ça jusqu'à 50097 (taille 10) avant de redescendre. Mais la longueur du plus long chemin n'est pas directement reliée à la taille du graphe : certes, celui des mots de 10 lettres a plus de sommets, mais il est moins dense (moins d'arêtes), et contient donc probablement moins de longs chemins. Grâce à quelques scripts en Python, voici les réseaux obtenus pour les mots de taille
3,
4,
5,
6,
7,
8 (18 Mo pour le dernier...).
Première chose à faire, calculer les composantes connexes, les parties du graphes où toute paire de sommets est reliée par un chemin. Pour cela
(merci Anaïs !) la bibliothèque iGraph en R fait tout le boulot.
Téléchargez-la, installez-la (
install.packages("igraph")), puis lancez le code suivant :
library(igraph)
g<-read.graph("http://philippe.gambette.free.fr/Blog/2011Scrabble/Mots6.graph.txt",format="ncol")
cc<-clusters(g)
cc$csize
On obtient une composante connexe de taille 13865, et 5 de taille 2. Pour avoir la composition des cinq paires :
V(g)[which(cc$membership==1)-1]
V(g)[which(cc$membership==2)-1]
...
Les 5 paires sont donc : {rococo, corozo}, {hiboux, bijoux}, {puffin, muffin}, {okoume, loukoum}, {zozota, zozote}.

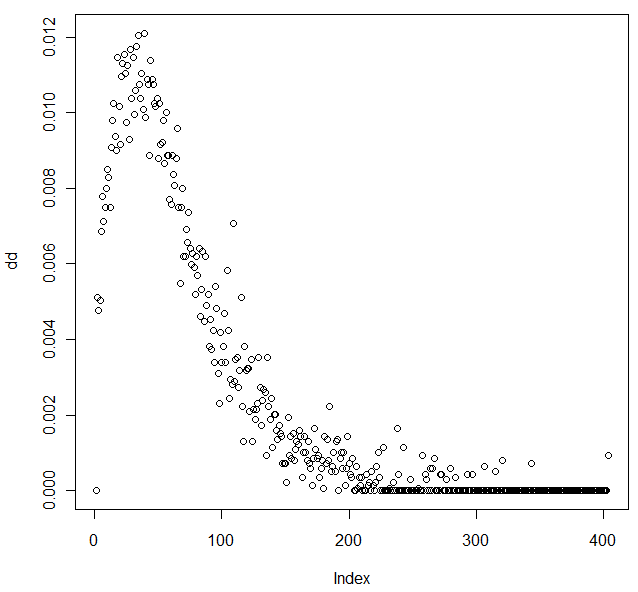
dd <- degree.distribution(g)
plot(dd)
On obtient l'image ci-contre, qui sent le
Poisson...
Quelle est la taille du plus long chemin dans ces graphes ? Eh bien ce problème est
NP-complet (difficile à résoudre pour un ordinateur), et je n'ai pas encore essayé de le soumettre
(pour les mots de taille 3, car je doute qu'il arrive à traiter un graphe à 10000 sommets et 400000 arêtes) au programme linéaire en nombres entiers récemment ajouté par
Nathann dans
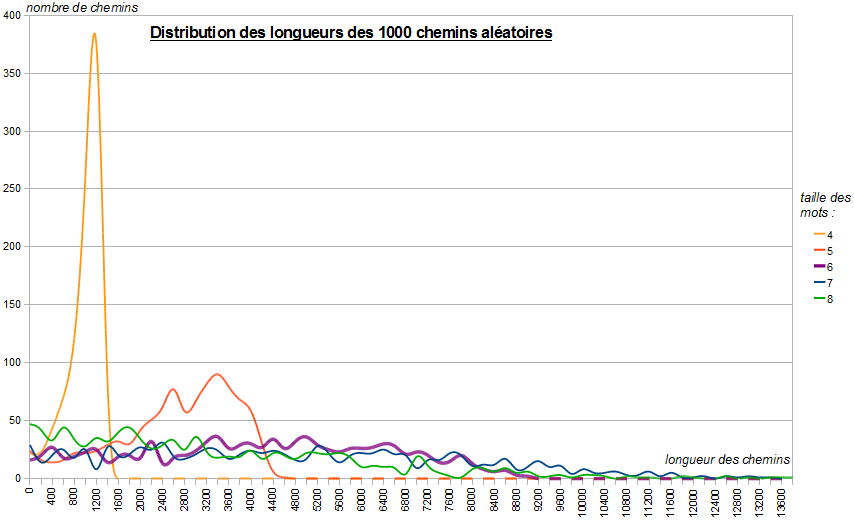
Sage (au moins j'ai - enfin - installé le logiciel). En revanche j'ai programmé un script qui lance un millier de chemins au hasard, en partant d'un sommet également choisi au hasard, et enregistre la taille de chacun des chemins obtenus.
J'obtiens les valeurs moyennes suivantes : la longueur maximale parmi tous les chemins trouvés augmente jusqu'à 8 lettres inclus (je n'ai pas testé les graphes pour les mots de taille supérieure), en revanche la longueur moyenne des chemins atteint un maximum pour le graphe des mots de sept lettres (cliquez sur le graphique pour voir la distribution des longueurs de chemins obtenue) :

Vous me direz qu'en calculant simplement le degré moyen des sommets du graphe, on obtenait justement un maximum pour une taille de mots de 6, avec un nombre moyen de voisins de 28,7 qui correspond à peu près à la valeur où le pic de la loi de Poisson est atteint ci-dessus... J'aimerais bien savoir comment Eliane de Bruxelles a choisi la taille de 6 quand elle a conçu ce jeu. En tout cas c'était bien trouvé, et il ne reste plus qu'à trouver quelques milliers de participants pour commencer à rendre le jeu difficile... A moins que vous ne vouliez vous lancer dans une stratégie de blocage du jeu, en l'orientant vers un "cul-de-sac", soit en faisant revenir le chemin vers des sommets déjà visités, soit vers des sommets de faible degré...
Si vous avez participé au mème, et que vous avez une liste différente de celles montrées ci-dessus, ça m'intéresse, dans la perspective d'un prochain billet sur le sujet : indiquez en commentaire une adresse de page web où vous l'avez placée, ou
envoyez-la moi par courriel en indiquant dans le sujet "Scrabble International". Et si vous voulez lancer le mème sur la blogosphère, faites-vous plaisir, en
citant des blogs pour les inciter à propager la chose ! Plutôt des blogs féminins, au vu des prénoms dans mes listes...
 Voter pour ce billet sur Wikio
Voter pour ce billet sur Wikio


 La solution est montrée en rouge. Comment l'ai-je trouvée ? Le problème est NP-complet, il n'existe donc probablement pas d'algorithme rapide (qui s'exécutera en temps polynomial par rapport à la taille de l'entrée du problème) pour le résoudre. Cependant, il existe un moyen rapide en pratique pour de petites instances du problème : le coder par un programme linéaire en nombres entiers
La solution est montrée en rouge. Comment l'ai-je trouvée ? Le problème est NP-complet, il n'existe donc probablement pas d'algorithme rapide (qui s'exécutera en temps polynomial par rapport à la taille de l'entrée du problème) pour le résoudre. Cependant, il existe un moyen rapide en pratique pour de petites instances du problème : le coder par un programme linéaire en nombres entiers 














{kind=link}
{kind=link}