Claviers espions : usure et fréquence de lettres
Dur dur de poster après une période silencieuse sur son blog... Reprendre un billet vaguement réveillé par un autre d'un blog influent ? Ficeler un rapport peu concluant sur l'influence de la plateforme sur le classement d'un blog ? Non, il faut un nouveau résultat fort, mêlant une idée théoriquement ingénieuse et calculable en pratique, un vrai projet de longue haleine qui montre qu'on n'a pas chômé...
Tout est parti de deux touches de clavier défaillantes. Delphine, déjà à l'origine de quelques posts sur ce blog, notait que les deux touches qui s'étaient détachées de son clavier faisaient partie du mot-clé principal de sa thèse. Il n'en fallait pas plus pour me faire envisager une forte corrélation entre l'usure des touches et leur fréquence d'utilisation (aussi remarquée ici par exemple), et rechercher les moyens de mesurer tout ça... et d'en déduire des choses.

Par chance, mon clavier Dell reflète assez bien son utilisation (ceux de certains Mac aussi apparemment, voire les claviers NMB Technologies), au bout d'un an. Mon "S" est par exemple presque complètement effacé. Mais surtout, si on regarde de plus près, les touches fréquemment utilisées sont vraiment usées, le plastique y est plus lisse, et elles réfléchissent beaucoup mieux la lumière. Je ne sais pas ce que ce polissage implique sur l'absorption de matières toxiques du bout des doigts, mais en tout cas il permet de faire des mesures : en éclairant le clavier par dessus et en prenant la photo de travers, les zones très réfléchissantes apparaissent plus sombres que le reste. Il faut alors quantifier l'usure à partir de la photo. Si l'on veut des résultats très précis, on peut s'amuser à faire du traitement d'image et mesurer l'intensité sur les portions de photo qui correspondent aux touches. Ca demande un gros travail, surtout de normalisation de l'image... alors qu'on peut procéder plus simplement : construire un quadrillage 5x5, le coller sur chaque touche, et compter les carreaux, parmi ces 25, qui sont sombres. En fait, pour les premières lettres, on compte les carreaux pour préparer quelques étalons, après, on compare avec les lettres dont l'usure a déjà été évaluée.
Il faut alors quantifier l'usure à partir de la photo. Si l'on veut des résultats très précis, on peut s'amuser à faire du traitement d'image et mesurer l'intensité sur les portions de photo qui correspondent aux touches. Ca demande un gros travail, surtout de normalisation de l'image... alors qu'on peut procéder plus simplement : construire un quadrillage 5x5, le coller sur chaque touche, et compter les carreaux, parmi ces 25, qui sont sombres. En fait, pour les premières lettres, on compte les carreaux pour préparer quelques étalons, après, on compare avec les lettres dont l'usure a déjà été évaluée.
Une fois ces quantités d'usure obtenues, on peut les comparer avec les fréquences de lettres en français. Pour cela, on me l'a confirmé dans mon cours de biostats cette année, rien ne vaut un joli diagramme XY :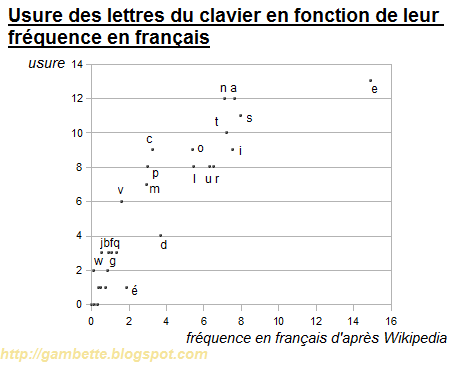
La corrélation est nette (coefficient 0,89), toutefois la relation entre les deux variables semble n'être pas exactement linéaire. Essayons d'élever l'usure au carré, ça semble mieux fonctionner (coefficient de corrélation 0,92), même si ce n'est pas parfait :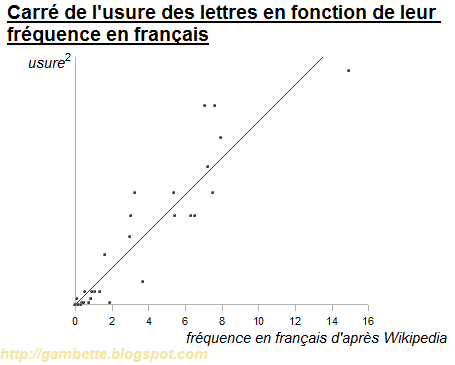
Qu'est-ce qui pourrait expliquer ces variations par rapport à la distribution moyenne des lettres en français ? Les gros joueurs de jeux vidéos ont apparemment leurs touches fétiches, je pense que ma forte usure de C et V vient de mon abus de raccourcis pour le copier coller, pour W c'est sûrement les adresses web. De plus, j'utilise mon ordinateur pour écrire à la fois en français et en anglais. Tiens tiens, et si j'utilisais l'usure des touches pour évaluer à quelle fréquence je tape en anglais ou en français ?
L'idée est donc que la distribution de l'usure n'est pas semblable à celle du français, mais à une combinaison linéaire de celle du français et de l'anglais. J'appelle U(l) ma fréquence d'utilisation de la lettre l, F(l) (respectivement A(l)) sa fréquence d'utilisation en français (resp. en anglais), et j'appelle x le ratio de ce que je tape en français par rapport à tout ce que j'écris avec mon ordinateur. U est donc une loi mélange de F et A : U(l) = x F(l) + (1-x) A(l). J'essaie de trouver x en connaissant une approximation de U, de F et de A pour toute lettre. Pour cela, je vais calculer le membre de droite pour toutes les valeurs de x entre 0 et 1, et évaluer la corrélation avec U. Tout peut se faire avec un tableur, ça se passe ici.
J'en profite pour une petite digression sur le coefficient de corrélation de Pearson, implémenté par COEFFICIENT.CORRELATION dans tout tableur digne de ce nom, que j'avais utilisé dans certains posts précédents sans comprendre sa formule magique. En fait, la formule est tout à fait naturelle une fois qu'on a compris que pour normaliser des distributions, classiquement, on divise les valeurs par l'écart type, avant de soustraire la moyenne (merci encore au cours de biostats, décidément ces modules doctoraux ont du bon quand on les choisit soi-même...).
Bref, passons aux résultats. J'utilise trois distributions de fréquences de lettres en français trouvées sur internet pour F, deux pour l'anglais et la distribution A. A chaque fois je calcule la valeur optimale de x. Je termine par une moyenne de ces valeurs de x : 0.81 (avec selon la distribution une variation inférieure à 10%). Bref, environ 1/5 de ce que je tape est en anglais.
A quel point la méthode présentée ici est fiable ? D'une part, il est connu que les fréquences de lettres varient selon le corpus utilisé. D'autre part, le coefficient de corrélation que je tente de maximiser afin de trouver le ratio x est peut-être trop sensible à de petites variations sur les fréquences de lettres. Pour tester ça, j'ai collé un bout de texte anglais à un bout de texte français (en connaissant le ratio x, donc) et j'ai essayé de le retrouver par la méthode de maximisation du coefficient de corrélation. Pour une étude plus sérieuse, j'aurais peut-être essayé un corpus de textes variés, là au vu des résultats je me suis contenté de mon premier essai. J'ai utilisé cet outil en ligne de calcul de fréquence de lettres, qui fournit des pourcentages de fréquences arrondis à l'entier près (pas très précis, donc, à peu près autant que mes mesures sur le clavier). J'ai copié le premier article du Monde que j'ai eu sous les yeux dans mon flux RSS, concaténé au texte de la page d'accueil de l'outil, en anglais donc (remarquez que ces deux textes sont très courts). Puis appliqué la méthode, avec les deux distributions de fréquences pour l'anglais et les trois pour le français. En faisant la moyenne des coefficients trouvés, j'obtiens 0,79 alors que la valeur réelle était 0,81 (8327 octets pour le texte français, 1904 pour l'anglais), soit à peine 3% d'erreur (et pour chaque couple de distributions de fréquences anglais/français, moins de 10% d'erreur).
J'ai utilisé cet outil en ligne de calcul de fréquence de lettres, qui fournit des pourcentages de fréquences arrondis à l'entier près (pas très précis, donc, à peu près autant que mes mesures sur le clavier). J'ai copié le premier article du Monde que j'ai eu sous les yeux dans mon flux RSS, concaténé au texte de la page d'accueil de l'outil, en anglais donc (remarquez que ces deux textes sont très courts). Puis appliqué la méthode, avec les deux distributions de fréquences pour l'anglais et les trois pour le français. En faisant la moyenne des coefficients trouvés, j'obtiens 0,79 alors que la valeur réelle était 0,81 (8327 octets pour le texte français, 1904 pour l'anglais), soit à peine 3% d'erreur (et pour chaque couple de distributions de fréquences anglais/français, moins de 10% d'erreur).
Bref, je suis assez confiant pour placer une marge d'erreur de 10%, et affirmer qu'il est possible de deviner par cette technique la langue d'un utilisateur d'ordinateur Dell qui use raisonnablement son clavier. Pas mal sans utiliser de vrai clavier espion !
 Voter pour ce billet sur Wikio
Voter pour ce billet sur Wikio








5 commentaires:
Guyslain, apparemment allergique aux commentaires de blogs, me signale qu'il doute de ma dernière étape, celle qui valide vaguement la méthode pour trouver le pourcentage de français dans un texte franco-anglais à partir uniquement des fréquences de lettres.
Evidemment ce billet n'est pas une publication scientifique, je me permets donc parfois, quand la première expérience testée m'indique de bons résultats, de m'en satisfaire. Malgré tout, après son commentaire, j'ai renouvelé l'expérience 3 fois : 2 fois sur des textes similaires (moins de 10Ko), pour tomber sur une erreur sur l'estimation de x de 3% et 4%. La troisième expérience était très défavorable : j'ai choisi un article parlant du même sujet (la prise du tanker par des pirates au large de la Somalie) sur le site du Monde et de la BBC : dans ce cas la méthode arrive moins bien à différencier les langues, elle répond 51% de français alors qu'il y en avait 61% (soit 16% d'erreur).
Bref, n'hésitez pas à approfondir ces tests, voire m'indiquer des publications qui traitent du sujet. Ca me semble intéressant en soi, même s'il me paraît évident que des méthodes plus fiables (ne serait-ce que fonctionnant avec les fréquences des n-grammes) existent pour ce problème.
C'est bon ça comme étude... Du presque Freakonomics !!!
Héhé, je ne sais pas si ce sera l'avis des autres doctorants du labo qui ont reçu un Dell en même temps que moi quand j'irai les harceler pour connaître leurs usures de touches...
Marrant ce truc ...
J'adore le coté spontané de la déclinaison scientifique d'un constat somme toute banal.
Moi j'aurais conclus en me demandant quel nouveau clavier j'allais acheté mais bon ...
En poursuivant la réflexion à mon niveau (!) la question qui me vient est : Tout cela m'indiquerait-il quelle devrait être la meilleure disposition du clavier ? n'est-ce pas positionner les touches les plus usées sous les doigts les plus "agile" avec un déplacement relatif des poignets minimisés entre les divers niveaux d'usure et l'affectation à une main.
cela existe : le dvorak ! personnellement j'utilise le dvorak bépo (adapté à la langue française) www.bepo.fr et effectivement les touches les plus usées sont celles de la position de repos
Enregistrer un commentaire