J'avais prévenu dans mon dernier billet, aujourd'hui on parle de choses techniques : la marge d'erreur de mon calcul. Rien de terrible non plus, hein, les calculs sont de niveau lycée... Et en fin de billet, quand même quelques éléments de méthodologie pour minimiser l'erreur. Résumé de l'épisode précédent : j'ai choisi une hiérarchie de termes qui apparaissent de plus en plus haut dans Google Trends, pour évaluer par règles de trois successives le niveau du terme le plus recherché par rapport au moins recherché.
Pour mon calcul je m'étais initialement arrangé instinctivement pour que dans chaque paire de termes consécutifs, le premier ait un maximum environ 2 fois plus haut que le précédent. En effet, la marge d'erreur absolue de lecture de la valeur des courbes est d'environ 1 pixel. Sauf que cette erreur absolue ne correspond pas à la même erreur relative pour la courbe du dessus et celle du dessous. Celle du dessus culmine toujours à 113 pixels : 1 pixel d'erreur c'est donc moins de 1%. Mais pour celle du dessous, si elle culmine à 50 pixels, ça fera 2% d'erreur. Si elle ne dépasse jamais 3 pixels, c'est plus de 30% d'erreur ! Alors dans ce cas, doit-on choisir une hiérarchie de courbes qui sont très proches les unes des autres ? Pas nécessairement, puisque dans ce cas effectivement on réduit l'erreur à chaque étape du calcul, pour deux termes consécutifs, mais on augmente le nombre de termes (et donc d'erreurs successives) entre le moins recherché sur Google, et le plus recherché.
Evidemment, ce délicat compromis que je viens d'exprimer avec des mots, je n'ai pas pu m'empêcher de le modéliser mathématiquement. Je vais appeler a le rapport entre la hauteur max de la courbe la plus haute et celle de la plus basse parmi deux consécutives (et donc a>1). Pour simplifier le problème je considère que dans toute mon échelle de termes, ce rapport est constant. Ainsi, idéalement, j'aimerais trouver un mot 1 cherché x fois par jour sur Google, un mot 2 cherché ax fois par jour, un mot 3 cherché a2x fois par jour... un mot n+1 cherché anx fois par jour.
Maintenant, exprimons cette histoire d'erreur à chaque étape entre deux mots consécutifs : au lieu de lire une hauteur de k pour un mot et ak=113 pour le mot suivant, disons que je me trompe d'un pixel, à chaque fois trop haut (c'est une hypothèse pessimiste, en réalité, l'erreur alterne probablement, une fois on lit trop haut, une fois trop bas, et ça compense...). Pour mon calcul, s'il n'y avait pas d'erreur, par la règle de 3 je devrais trouver comme valeur du nombre de recherches du terme le plus haut :
x.113/k = x.ak/k = xa
Problème, je fais 1 pixel d'erreur, et donc quand j'applique la règle de 3 j'obtiens :
x.113/(k+1) = x.113/(113/a+1) = x.113a/(113+a)
Ainsi à chaque étape je multiplie par 113a/(113+a) au lieu de multiplier par a, donc pour le terme le plus recherché, je trouve
x(113
a/(113+
a))
n au lieu de
xan. Je sous-estime donc la valeur réelle : ainsi pour minimiser l'erreur, je dois maximiser ma valeur calculée, donc trouver la valeur de
a>1 qui maximise
x(113
a/(113+
a))
n.
Deuxième partie du raisonnement maintenant : le nombre d'étapes, c'est à dire n+1 termes, certes... mais ce
n dépend de
a. En effet, considérons qu'on s'est fixés le terme le moins recherché (
x fois) et le terme le plus recherché (
x'=
xan fois). Alors
x'=
xen ln a, d'où ln(
x'/
x)=
n ln
a et donc
n=ln(
x'/
x)/ln
a.
Injectons ça dans la formule du haut, on a sous-estimé tous les termes de la hiérarchie, et le plus haut a été évalué à :
x(113a/(113+a))ln(x'/x)/ln a
expression qu'on doit donc maximiser par rapport à a. Commençons par une analyse de cette fonction aux limites (mmmmh, les bons souvenirs de première !). En 1
+, l'intérieur de la parenthèse est inférieur à 1, et l'exposant tend vers +∞, donc l'expression tend vers 0. En +∞, l'exposant tend vers 0, et l'intérieur de la parenthèse vers 113, le tout tend donc vers 1. Ca tombe bien, c'est assez intuitif, ça exprime mathématiquement le dilemme que j'exprimais au second paragraphe... Bon bref, tout ceci ne nous dit pas où se situe son maximum. Et là ni
Ahmed le Physicien, ni
Julian le Mathématicien, armés respectivement de Mathematica et Maple, ne me fournissent une belle formule, il reste quelques méchants
RacineDe(...) dans l'expression.
Pas grave, on va se contenter d'en trouver une
approximation à l'aide d'un tableur. Le fichier est
ici, et voici la courbe obtenue pour un rapport de 20 000 entre le mot le moins cherché et le plus cherché
(c'est de l'ordre de grandeur de celui que j'ai dans ma hiérarchie de termes) :

Ainsi l'erreur minimale est atteinte pour une
valeur de a d'environ 2,75 (soit une hauteur maximale de 41 pixels pour la courbe du bas). Elle est alors d'un peu moins de 25%. C'est certes conséquent, mais rappelez-vous qu'on a choisi le scénario où les erreurs se cumulaient par sous-estimation systématique. Alors il me reste cette question théorique intéressante :
peut-on calculer l'espérance de l'erreur sur la valeur calculée du terme le plus fréquemment cherché, si à chaque étape l'erreur oscille aléatoirement à chaque mesure entre -1 et +1 pixel ?
On remarque aussi que la courbe croît plus vite à gauche qu'à droite : comme suggéré en vert sur le graphique, il semble qu'
il vaudrait mieux choisir une hiérarchie telle que les nombres de recherches des mots de référence consécutifs ont un rapport de 4, plutôt qu'un rapport de 2.
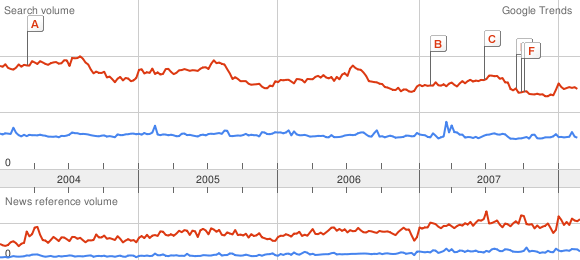
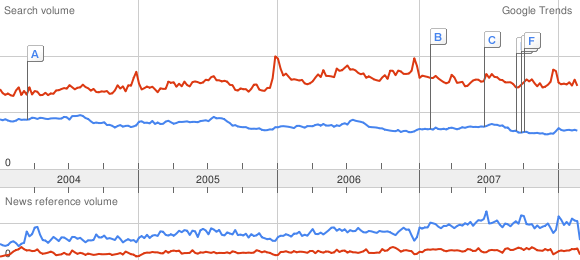
Maintenant, voici quelques autres moyens d'améliorer la précision du calcul. Tout d'abord la précision de la mesure : au lieu de simplement mesurer le maximum où on sait qu'il y a une erreur inévitable, on peut tenter de le calculer à partir de mesures qui contiennent moins d'erreur. Je reprends l'exemple
du billet précédent avec cat, dog, et phone:
Comparaison cat ~ dog (courbe 1) : 65 px
~ 113 px
Comparaison dog ~ phone (courbe 2) : 69 px
~ 113 px
Sauf qu'au lieu de mesurer le maximum de dog, on peut l'évaluer de la façon suivante faire la moyenne des valeurs sur la courbe 1 de dog, et la moyenne des valeurs sur la courbe 2 de dog. On en déduit alors un changement d'échelle tout à fait précis. On sait alors que le maximum de dog sur la courbe 1 est atteint à 113 pixels exactement, puisque ça semble être la valeur de référence dans les dessins Google Trends. On multiplie donc cette valeur par le changement d'échelle, et le tour est joué !
Alors maintenant autre problème : comment obtenir la moyenne des valeurs d'une courbe Google Trends ? Avec le CaptuCourbe, évidemment ! Alors là aussi, attention : il arrive que certaines valeurs ne soient pas récupérées par le CaptuCourbe
(problème de couleur, par exemple la courbe est coupée par une ligne verticale noire accrochée à une bulle de légende Google News). Il s'agit donc de prendre garde à effectuer la moyenne des deux courbes sur des valeurs bien récupérées !
Autre chose, le CaptuCourbe, par sa méthode de capture, n'est
pas très précis puisqu'il
récupère tous les pixels de la couleur de la courbe, et en fait la moyenne. J'ai donc développé une nouvelle version, bientôt en ligne, qui permet de récupérer non pas la moyenne mais
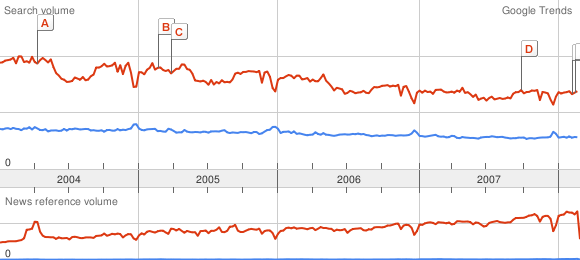
le max des hauteurs des pixels d'une certaine couleur. C'est cette fonction que j'utilise dans ma méthode pour calculer le max, en revanche c'est toujours celle de la moyenne que j'utilise pour calculer les moyennes des courbes. Ce petit détail n'en est pas un, comme le prouve par exemple la
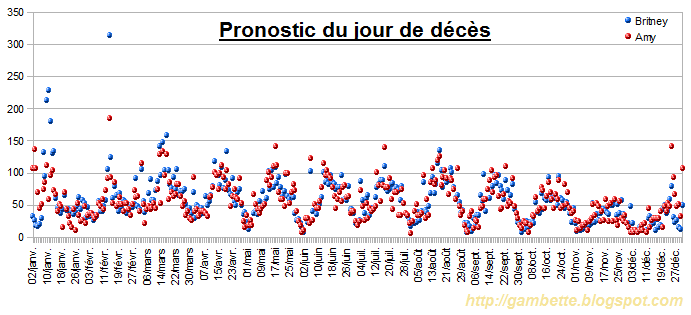
courbe Google Trends de Britney Spears, que j'ai capturée par la méthode du max, et de la moyenne :

Une erreur de 20% dans la mesure de plusieurs pics en utilisant la moyenne des pixels de même couleur, vraiment pas négligeable !
Pour terminer cette série de billets sur l'échelle verticale de Google Trends, il me reste encore quelques questions. Tout d'abord préciser la "valeur du foo". Grâce à des commentaires pertinents sur
mon premier billet, je n'en suis pas loin. Je pourrai alors tenter d'automatiser toute la chaîne de récupération de courbes, mesures, et calculs, décrite dans le premier billet, pour fournir un programme qui précise sur une courbe Google Trends à combien de visiteurs correspondent les pics. Ceci dit je ne promets rien, ça vaudrait peut-être le coup d'attendre si l'API que Google prépare fournira ces données.
L'estimation du nombre de recherches pour un mot clé est en tout cas un défi intéressant, j'ai découvert le logiciel gratuit
GTrends Made Easy qui propose de telles estimations par une méthode similaire à celle que j'ai présentée ici
(en fait il ne fait qu'une seule règle de trois, en comparant le terme cherché avec un mot dont il connaît le nombre de recherches Google par un bon placement Google sur ce mot, et donc se limite aux mots qui apparaissent entre 5 et 50000 fois par jour, c'est à dire inférieurs à 100 foo), qui avait été décrite sur cette vidéo
YouTube. Dommage que leurs auteurs n'aient pas poussé leur idée plus loin en enchaînant les changements d'échelle au lieu de se limiter à un.
 Attention, comme toujours avec les "Google numbers", les résultats sont à prendre avec des pincettes. Toutefois, le premier souci qui est celui de la polysémie des expressions recherchées est plutôt bien réglé par le "en 2012". Il précise le contexte des élections présidentielles est correct, et permet par exemple d'assurer que "Royal" signifie bien "Ségolène Royal" (ce qui est rarement garanti dans les recherches Google de ce genre). Je ne vous assure pas de la pertinence de rechercher cette expression en décembre 2011, mais pour l'instant, les résultats trouvés concernent presque tous le sujet. Petit problème aussi, différencier père et fille chez les Le Pen : la variation entre "candidate" et "candidat" permet de donner des indications sur les scores des deux.
Attention, comme toujours avec les "Google numbers", les résultats sont à prendre avec des pincettes. Toutefois, le premier souci qui est celui de la polysémie des expressions recherchées est plutôt bien réglé par le "en 2012". Il précise le contexte des élections présidentielles est correct, et permet par exemple d'assurer que "Royal" signifie bien "Ségolène Royal" (ce qui est rarement garanti dans les recherches Google de ce genre). Je ne vous assure pas de la pertinence de rechercher cette expression en décembre 2011, mais pour l'instant, les résultats trouvés concernent presque tous le sujet. Petit problème aussi, différencier père et fille chez les Le Pen : la variation entre "candidate" et "candidat" permet de donner des indications sur les scores des deux. Voter pour ce billet sur Wikio
Voter pour ce billet sur Wikio













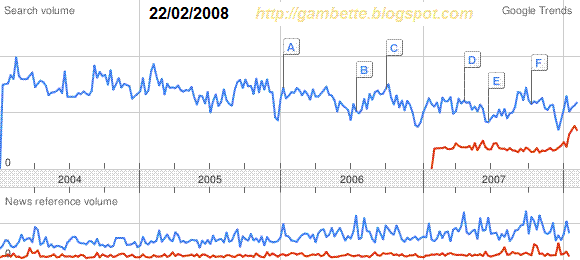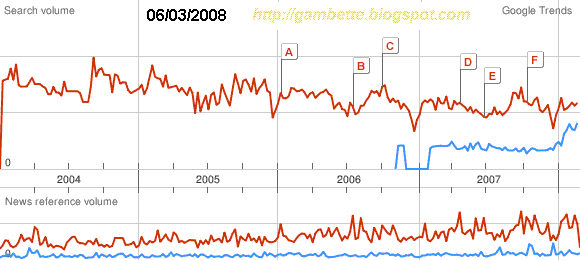
 Quoi qu'il en soit, suivre les premières heures m'a permis de noter la réactivité des divers moteurs de recherche et outils de suivi de la blogosphère ou plus généralement du web. Comme je l'ai mentionné ci-dessus, c'est la
Quoi qu'il en soit, suivre les premières heures m'a permis de noter la réactivité des divers moteurs de recherche et outils de suivi de la blogosphère ou plus généralement du web. Comme je l'ai mentionné ci-dessus, c'est la 






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}